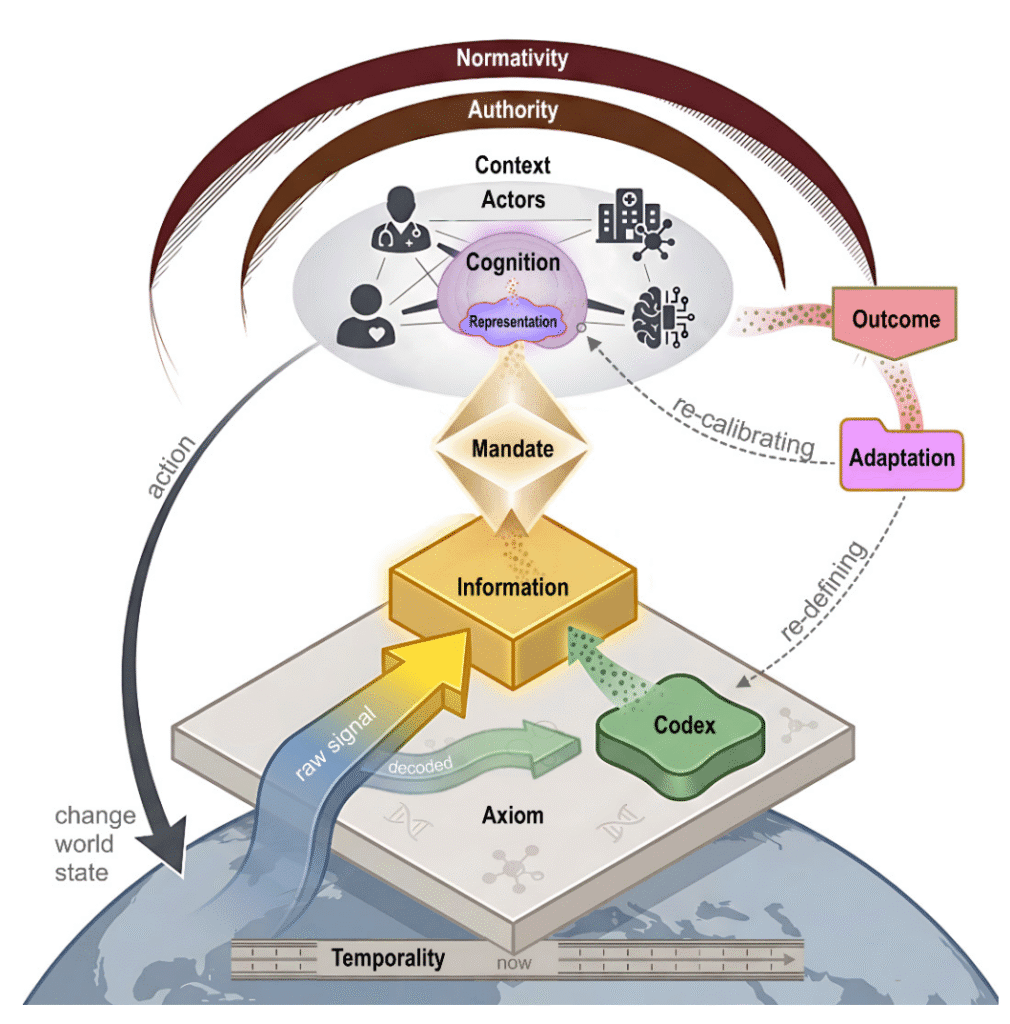
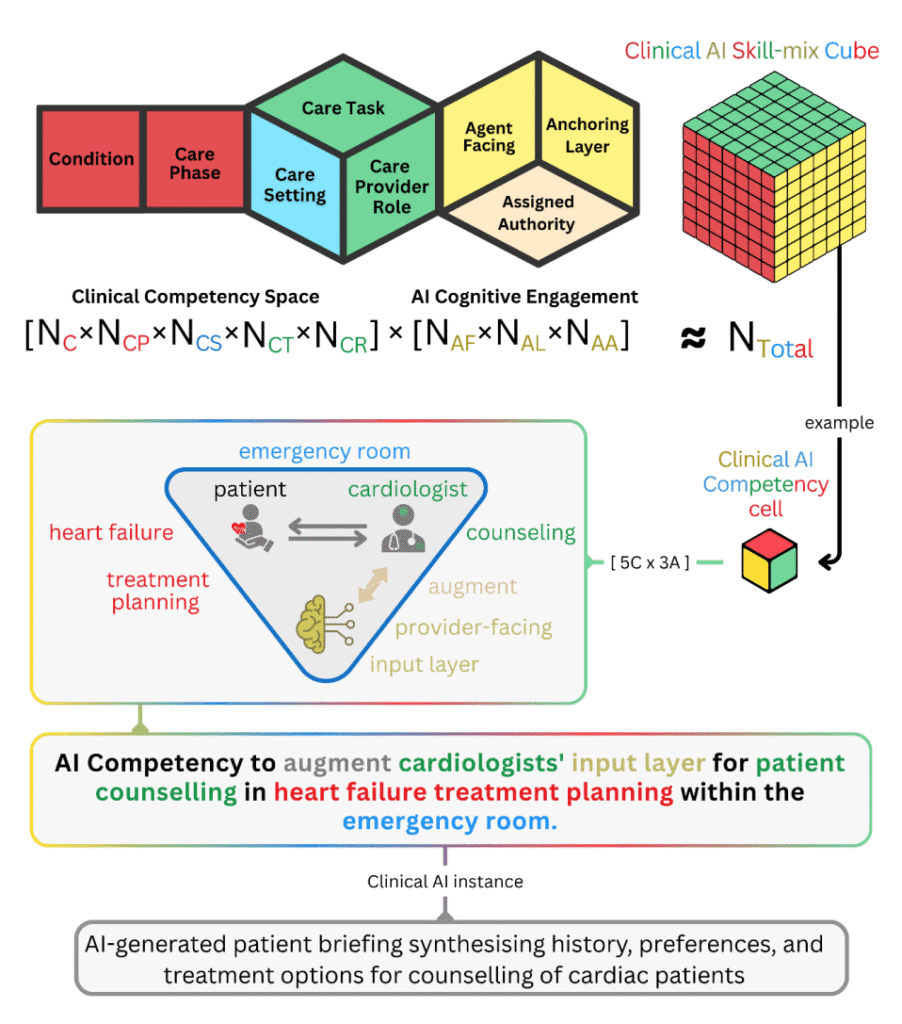
We propose three interconnected models grounded in validated principles of clinical cognition and human factors. The Clinical World Model formalizes care as a tripartite interaction among Patient, Provider, and Ecosystem, recovering structure that prior frameworks share implicitly rather than introducing an independent account. Parallel decision-making architectures specify how providers, patients, and AI agents transform information into action, mapping human cognitive components such as dual-process reasoning, illness scripts, and metacognitive monitoring onto their computational counterparts. The Clinical AI Skill-Mix then operationalizes competency through eight dimensions, five that characterize the clinical scenario (condition, care phase, care setting, provider role, and task) and three that specify how AI engages human reasoning (assigned authority, agent facing, and anchoring layer).
The combinatorial product of these dimensions defines a competency space of billions of distinct coordinates, and this scale has a direct structural implication. Validation within one coordinate provides minimal evidence for performance in another, rendering the competency space irreducible and indicating that a single-task model, however accurate, addresses only a small fraction of the competencies required for clinical action. The framework supplies a common grammar through which clinicians, regulators, and developers can specify, evaluate, and bound a given system in consistent terms, including the points at which authority shifts as agents hand off work to one another. On this account, the central question moves from whether clinical AI works to the competency coordinates in which a system has demonstrated reliability, and for whom.